ちょっとうれしかったので自慢。
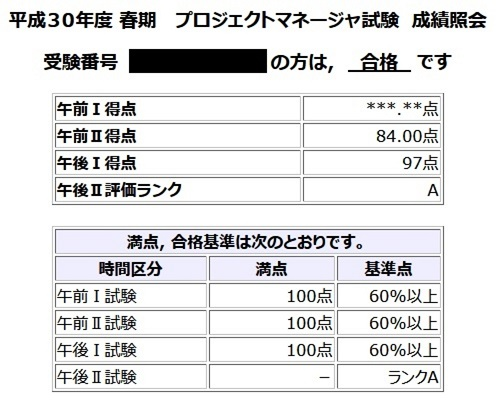
4月に受けた情報処理技術者試験のプロジェクトマネージャ試験(PM)に合格していました。
情報セキュリティスペシャリスト(SC)、ネットワークスペシャリスト(NW)、データベーススペシャリスト(DB)と
スペシャリスト系を3種類合格していたので特に目標感なく、受かったらラッキーぐらいで過ごしてました。
(会社の報奨金制度の関係で、エンベデッドスペシャリスト(ES)は報奨金なしなので、未受験...。)
最近では雨が降ったら受験してみて、晴れてたら釣りに行くような有様...。
でも決して楽勝の一発合格ではなく、2年前は受験していて、午後2の論文試験の判定がBで落ちてます。
SIerでインフラ系システムエンジニアとして働いていますが、技術が得意のはず(だと思っている)の人間でも、
年齢に応じて段々と管理業務の比重が高まっていく...。(進捗、課題、収支、契約...etc)
そういった背景というか、仕事柄というか経験を積めているから合格水準に達したのかもしれません。
でも、合格したからといってうまく仕事を回せているわけでもなく...。
寝る前に試験対策本を少しずつ読んで用語を頭に入れます。
試験前日には午前2問題の練習をして、8割ぐらいとれるのを確認したら、午後2の論文の解答例に目を通す感じです。
午後1は対策しません。当日興味のあるものを集中して解く、基本に忠実な回答に徹することをすれば、6割ぐらいは得点できると思います。
午後2は何故に通ったのかよくわからないので、割愛。
多分、受験テクニックもあると思いますが、本人の経験値が高い方が、様々な設問に対応できるので有利だと思います。
ちなみに私が勉強に使ったのは↓の本でした。
午後1については問1と2を選択しました。
問1は今はやりのクラウド(SaaS)に関する内容だったので、身近な感じで内容を理解しやすかったです。
問2は品質管理指標に関する話で内容が興味深くて解きながら面白いなと思いました。
問3はステコミ云々でややこしそうだったので選択しませんでした。
午後2は問2を選択しました。
本稼働間近で発見された問題についてどう対応したかを問われる問題でした。
プロジェクト実施上、課題はあるけど本番日は死守ということはよくある話なので、記述しやすい問題だったと思います。
システムテスト時にハードウェアのファームウェアバグに起因する問題をテーマに記述していきました。
テストで発生条件を特定して、それを実施しないように運用回避するみたいなことを書きました。
黒字が私の解答、赤字がIPA公式解答です。
■問1
設問1 (1) a
運用・保守費用の最小化
システム保守費用の最小化
設問1 (2) b
キャパシティ拡張の要否
契約した利用量を見直す必要性
契約条件に沿った利用になっていること
次契約の利用者数及びデータ容量
設問2 (1)
SaaSでは、データ容量に基づき課金されるため
データ容量を抑えて、費用負担を少なくしたいから
SaaSの利用にかかる費用負担を少なくしたいから
設問2 (2)
現行営業支援システムには役職コードが含まれていないため
現行営業支援システムでは役職コードを取得していないから
役職に応じたデータの閲覧に必要な利用者権限を適切に付与したいから
設問2 (3)
データの返却がされず、別のシステムへの移行ができなくなるリスク
新営業支援システムの保管データを失うリスク
設問3 (1)
要件定義以降の工程での手戻りのリスク
要件定義以降の工程での手戻りリスク
設問3 (2)
見直した業務プロセスでの業務負荷が許容範囲に収まること
営業部の担当者の業務負荷が許容範囲に収まること
設問3 (3)
過度な費用負担にならないようにするため
過度な費用負担にならないようにしたいから
■問2
設問1 (1)
設計限界品質に近づける活動
設計限界品質に近づける活動
設問1 (2)
自工程より前の工程での欠陥検出が不十分な状況
自工程よりも前の工程群での欠陥検出が不十分だった状況
設問2 (1)
テスト工程では前の工程よりスケジュールの制約が厳しいため
テスト工程は納期に近く、時間の余裕がないから
テスト工程は時間の制約で、手戻りをリカバリする余裕が少ないから
設問2 (2)
混入工程ごとの総欠陥数
混入工程ごとの総欠陥数
指標における分母
設問3 (1) イ
50.2
50.2
設問3 (1) ロ
58.0
58.0
設問3 (2)
予防のコストより対処のコストが小さいケース
対処のコストが、予防のコスト以下であったケース
設問3 (3)
新しい品質管理指標がα群とβ群のプロジェクト間で有意差があること
α群に関する新しい品質管理指標の数値が、β群よりも高いこと
両群について、新しい品質管理指標の結果に有意な差があること
4月に受けた情報処理技術者試験のプロジェクトマネージャ試験(PM)に合格していました。
情報セキュリティスペシャリスト(SC)、ネットワークスペシャリスト(NW)、データベーススペシャリスト(DB)と
スペシャリスト系を3種類合格していたので特に目標感なく、受かったらラッキーぐらいで過ごしてました。
(会社の報奨金制度の関係で、エンベデッドスペシャリスト(ES)は報奨金なしなので、未受験...。)
最近では雨が降ったら受験してみて、晴れてたら釣りに行くような有様...。
でも決して楽勝の一発合格ではなく、2年前は受験していて、午後2の論文試験の判定がBで落ちてます。
SIerでインフラ系システムエンジニアとして働いていますが、技術が得意のはず(だと思っている)の人間でも、
年齢に応じて段々と管理業務の比重が高まっていく...。(進捗、課題、収支、契約...etc)
そういった背景というか、仕事柄というか経験を積めているから合格水準に達したのかもしれません。
でも、合格したからといってうまく仕事を回せているわけでもなく...。
私の勉強方法
私の勉強方法としては、1週間前から天気予報を確認して試験当日が雨予報だったら、勉強開始です。寝る前に試験対策本を少しずつ読んで用語を頭に入れます。
試験前日には午前2問題の練習をして、8割ぐらいとれるのを確認したら、午後2の論文の解答例に目を通す感じです。
午後1は対策しません。当日興味のあるものを集中して解く、基本に忠実な回答に徹することをすれば、6割ぐらいは得点できると思います。
午後2は何故に通ったのかよくわからないので、割愛。
多分、受験テクニックもあると思いますが、本人の経験値が高い方が、様々な設問に対応できるので有利だと思います。
ちなみに私が勉強に使ったのは↓の本でした。

試験を振り返って
午前2については予定通りのスコアに落ち着いたので特に言うことなしです。午後1については問1と2を選択しました。
問1は今はやりのクラウド(SaaS)に関する内容だったので、身近な感じで内容を理解しやすかったです。
問2は品質管理指標に関する話で内容が興味深くて解きながら面白いなと思いました。
問3はステコミ云々でややこしそうだったので選択しませんでした。
午後2は問2を選択しました。
本稼働間近で発見された問題についてどう対応したかを問われる問題でした。
プロジェクト実施上、課題はあるけど本番日は死守ということはよくある話なので、記述しやすい問題だったと思います。
システムテスト時にハードウェアのファームウェアバグに起因する問題をテーマに記述していきました。
テストで発生条件を特定して、それを実施しないように運用回避するみたいなことを書きました。
私の午後1解答
以下、午後1の解答復元です。若干の言葉は違うかもしれませんが、意味は変わってないはず...。黒字が私の解答、赤字がIPA公式解答です。
■問1
設問1 (1) a
運用・保守費用の最小化
システム保守費用の最小化
設問1 (2) b
キャパシティ拡張の要否
契約した利用量を見直す必要性
契約条件に沿った利用になっていること
次契約の利用者数及びデータ容量
設問2 (1)
SaaSでは、データ容量に基づき課金されるため
データ容量を抑えて、費用負担を少なくしたいから
SaaSの利用にかかる費用負担を少なくしたいから
設問2 (2)
現行営業支援システムには役職コードが含まれていないため
現行営業支援システムでは役職コードを取得していないから
役職に応じたデータの閲覧に必要な利用者権限を適切に付与したいから
設問2 (3)
データの返却がされず、別のシステムへの移行ができなくなるリスク
新営業支援システムの保管データを失うリスク
設問3 (1)
要件定義以降の工程での手戻りのリスク
要件定義以降の工程での手戻りリスク
設問3 (2)
見直した業務プロセスでの業務負荷が許容範囲に収まること
営業部の担当者の業務負荷が許容範囲に収まること
設問3 (3)
過度な費用負担にならないようにするため
過度な費用負担にならないようにしたいから
■問2
設問1 (1)
設計限界品質に近づける活動
設計限界品質に近づける活動
設問1 (2)
自工程より前の工程での欠陥検出が不十分な状況
自工程よりも前の工程群での欠陥検出が不十分だった状況
設問2 (1)
テスト工程では前の工程よりスケジュールの制約が厳しいため
テスト工程は納期に近く、時間の余裕がないから
テスト工程は時間の制約で、手戻りをリカバリする余裕が少ないから
設問2 (2)
混入工程ごとの総欠陥数
混入工程ごとの総欠陥数
指標における分母
設問3 (1) イ
50.2
50.2
設問3 (1) ロ
58.0
58.0
設問3 (2)
予防のコストより対処のコストが小さいケース
対処のコストが、予防のコスト以下であったケース
設問3 (3)
新しい品質管理指標がα群とβ群のプロジェクト間で有意差があること
α群に関する新しい品質管理指標の数値が、β群よりも高いこと
両群について、新しい品質管理指標の結果に有意な差があること